 Software Development
Software Development
 Security Services
Security Services
 Cloud Services
Cloud Services
 Other Services
Other Services










 TechMagic Academy
TechMagic Academy
Data Lake VS. Data Warehouse: Which Effective For Data Management

Director of Cloud and Cybersecurity, AWS Expert, big fan of SRE. Helps teams to improve system reliability, optimise testing efforts, speed up release cycles & build confidence in product quality.

As organizations generate and accumulate a sea of data, a robust and intelligent data infrastructure becomes vital.
Have you ever thought about how to manage and extract insights from this data efficiently?
McKinsey & Company highlights businesses adept at harnessing data can potentially boost their operating margins by a substantial 60%. This is precisely where data warehouses and data lakes come into play, offering robust methodologies for storing and analyzing data. Yet, it's essential to recognize these two technologies possess distinct differences.
The question emerges: what are the defining characteristics distinguishing a data lake vs a data warehouse? What considerations weigh in when determining the optimal fit for your enterprise – a data warehouse or a data lake?
Remember that your choice of data infrastructure isn't just about bits and bytes – it's about using the full potential of your organization's most precious resource: data.
What is a Data Lake?
The data lake is a sizable, centralized storage, handling massive amounts of pure raw, unstructured, or semi-structured data until it's ready to be used, especially in data science and large-scale analytical processing.
Unlike conventional databases, a data lake holds data in its pure, unprocessed form. It serves as a centralized hub encompassing both source and transformed data, ranging from structured data from relational databases (such as report tables) to semi-structured data (like CSV, JSON, logs), unstructured data (including emails, documents, and PDFs), and even binary data like images, audio, and video. Unlike their counterparts, data warehouses, and data lakes skip the need for a pre-set structure, allowing data to be stored in any format and retrieved with ease.
While a data warehouse structures data into files or folders, a data lake follows a flat architecture. Each data element is equipped with comprehensive metadata tags and possesses a unique identifier. When needed, you can query the data lake to fetch relevant information. This empowers you to analyze a targeted subset of data, facilitating precise responses to specific business queries.
Data engineering teams can pick metadata, storage, and compute technologies according to system requirements. The toolkit for data lakes often includes:
- Metadata: Think Hive, Amazon Glue, and Databricks.
- Storage: S3, Google Cloud Storage, Microsoft Azure Blob Storage, and Hadoop HDFS.
- Compute: Apache Pig, Hive, Presto, and Spark.
- Common formats: JSON, Apache Parquet, Apache Avro, Apache Hudl, Delta Lake.
What is Data Warehouse?
Data warehouse is a storage for your structured data, offering not just storage but also computational prowess. Its toolkit often revolves around the art of SQL queries for data analytics goals.
The data warehouse completes these functions:
- Data Extraction: Gathering data from various sources, ensuring nothing is left behind.
- Data Cleaning: Polishing the data gems, ensuring they shine without imperfections.
- Data Transformation: Crafting the data into a form ready for analysis and interpretation.
- Data Loading and Refreshing: Infusing fresh life into the repository, keeping it relevant and up to date.
These warehouses have a particular style of organization – a relational schema – that's fine-tuned for the art of reading data. This setup plays perfectly into online analytical processing (OLAP), enhancing the experience of meticulously extracted, transformed, and loaded (ETL) from various sources for insights. And here’s the twist: SQL queries are the magic wand behind functionalities like business intelligence (BI), reporting, and visualizations.
Looking for a Big Data solution?
Learn moreData warehouses can have one, two, or three levels. Among these, the three-tier architectural structure is the most prevalent:
- Bottom tier (data layer) – This is where data is ingested into the warehouse.
- Middle tier (application layer) – an Online Analytical Processing (OLAP) server manages the data.
- Top tier (presentation layer) – Designed for end-users, it offers dedicated tools and Application Programming Interfaces (APIs) for data extraction and analysis.
While data warehouses traditionally resided on-premises, an increasing number now utilize cloud storage to host and analyze vast data sets. Some of the leading cloud data warehouse platforms include:
- Microsoft Azure: Azure Synapse Analytics and Azure SQL Database
- AWS: Amazon Redshift
- Google Cloud Platform: BigQuery
- Snowflake Data Warehouse
Advantages of Data Lake
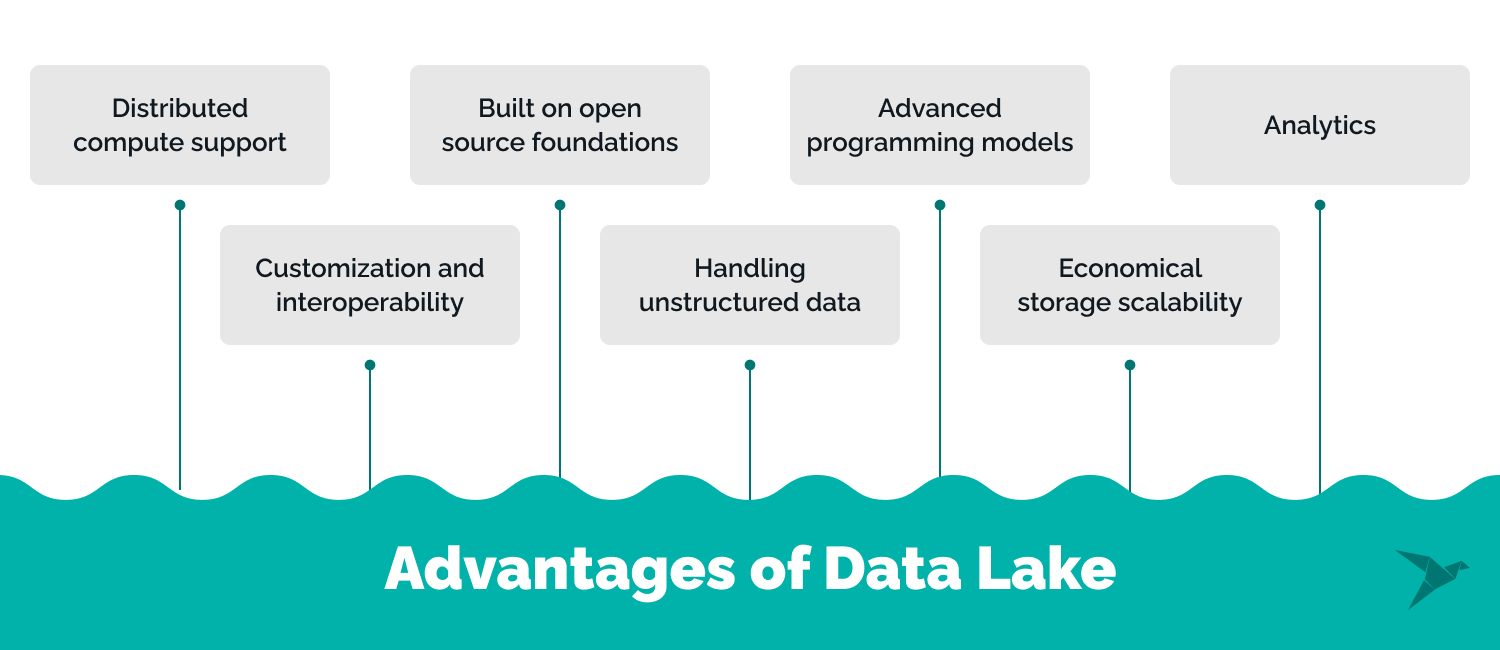
Distributed compute support
You can enhance query performance by segmenting data, strengthening fault tolerance, and get clear parallel data processing.
Customization and interoperability
Data lakes thrive on a "plug and chug", seamlessly integrating different components of your data stack. As your company's data requirements mature, this adaptability ensures smooth scalability.
Built on open-source foundations
Data lakes predominantly rest upon open-source technologies. This translates to reduced vendor dependency and offers extensive customization avenues, catering to enterprises with robust data engineering teams.
Handling unstructured data
From structured data like databases and spreadsheets to semi-structured sources like JSON and XML, and even entirely unstructured data like images and text documents – data lakes embrace it all. This unique flexibility allows you to capture, store, and process data from diverse sources without extensive data transformations.
Advanced programming models
Data lakes seamlessly integrate with big data technologies like Hadoop and Spark. This compatibility enables to performance of data science and machine learning, processing, distributed computing, and advanced analytics, enabling the managing of massive datasets efficiently.
Economical storage scalability
Data lakes excel in handling large volumes of data, making them a cost-effective solution for scalable storage. Traditional relational databases might become cost-prohibitive as data grows exponentially, while data lakes leverage affordable storage solutions to retain raw data for future analysis without straining your budget.
Analytics
Data lakes encourage a culture of exploration and experimentation. Since data can be ingested without needing upfront schema design, analysts can explore and derive insights from new data sources rapidly, fostering innovation and informed decision-making.
Data lakes redefine analytics by making previously untapped data accessible. Think log files, click-streams, social media interactions, and IoT device data – all unified within the data lake, paving the way for innovative analytical pursuits.
Challenges of Data Lakes
Data governance and quality assurance
The absence of rigid schemas and the ability to ingest data in its raw form can lead to a lack of standardized structures. This, in turn, raises concerns about data accuracy, consistency, and reliability. To mitigate this, meticulous data governance practices, including metadata management, data lineage tracking, and access controls, become essential.
Potential performance bottlenecks
While data lakes can accumulate vast amounts of data, retrieving insights through querying might encounter performance bottlenecks. Complex queries or large-scale processing can lead to prolonged query times or strained computational resources. Optimization strategies, partitioning, and indexing are essential to ensure timely query responses and efficient data processing.
Complexity in data processing
While data lakes empower diverse analyses, the schema-on-read approach can lead to complexities during data processing. The absence of upfront structuring necessitates considerable effort in data preparation and transformation at the query level. This can introduce difficulty in interpreting data accurately and may lead to time-consuming iterations.
Advantages of Data Warehousing
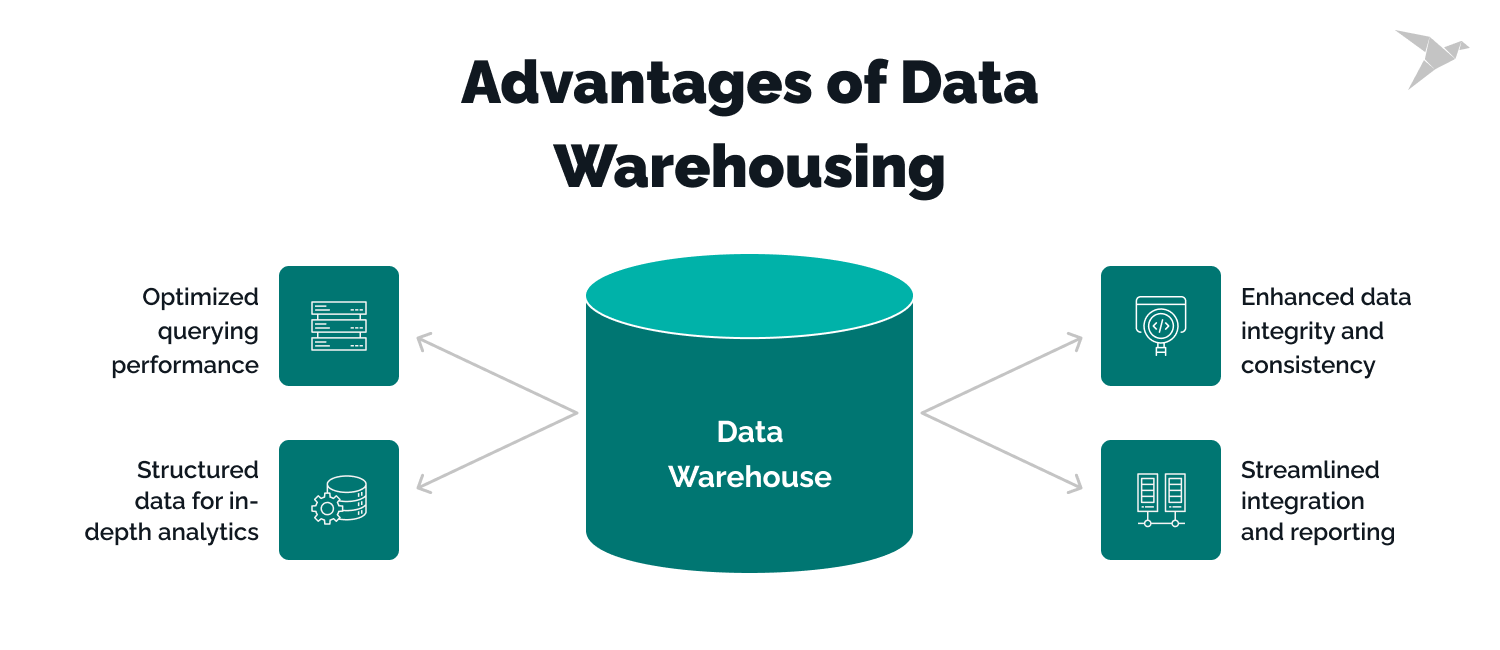
Optimized querying performance
Their structured architecture and indexing mechanisms ensure that complex queries, aggregations, and joins are executed quickly. This swift query response time empowers decision-makers with actionable insights in real-time.
Structured data for in-depth analytics
Well-defined connections between data elements facilitate complex analysis, making it easier to uncover patterns, trends, and correlations within your data. This structure ensures data is ready for meaningful interpretation.
Enhanced data integrity and consistency
Data warehouses enforce data integrity through predefined schemas and rigorous validation processes. This commitment to data accuracy provides the insights drawn from the warehouse are reliable and consistent.
Streamlined integration and reporting
Data warehouses act as central repositories, simplifying data integration from various sources for seamless reporting as data from different departments and systems converge within the warehouse. The resulting holistic view enhances reporting accuracy and cross-functional insights.
Challenges of Data Warehouses
Costs of implementation and maintenance
While data warehouses offer streamlined querying and analytics, their structured architecture demands substantial upfront investment and ongoing maintenance. Costs can escalate as data volumes grow, potentially straining the budget, especially for organizations with extensive data sets.
Potentially limited scalability
As data volumes grow, scalability becomes crucial. Ensuring the data warehouse can efficiently handle increased data loads while maintaining performance can be challenging.
Adapting to changing requirements
Data warehouses are designed to cater to predefined business questions and analytics needs. Adapting to new, unanticipated questions or changes in data requirements can be time-consuming and might necessitate significant alterations to the existing structure.
Handling unstructured data
While data warehouses excel with structured data, accommodating unstructured or semi-structured data poses challenges. With diverse data sources like social media streams and sensor data, fitting these unstructured pieces into the structured warehouse puzzle can be intricate.
Key Differences Between Data Warehouse vs Data Lake
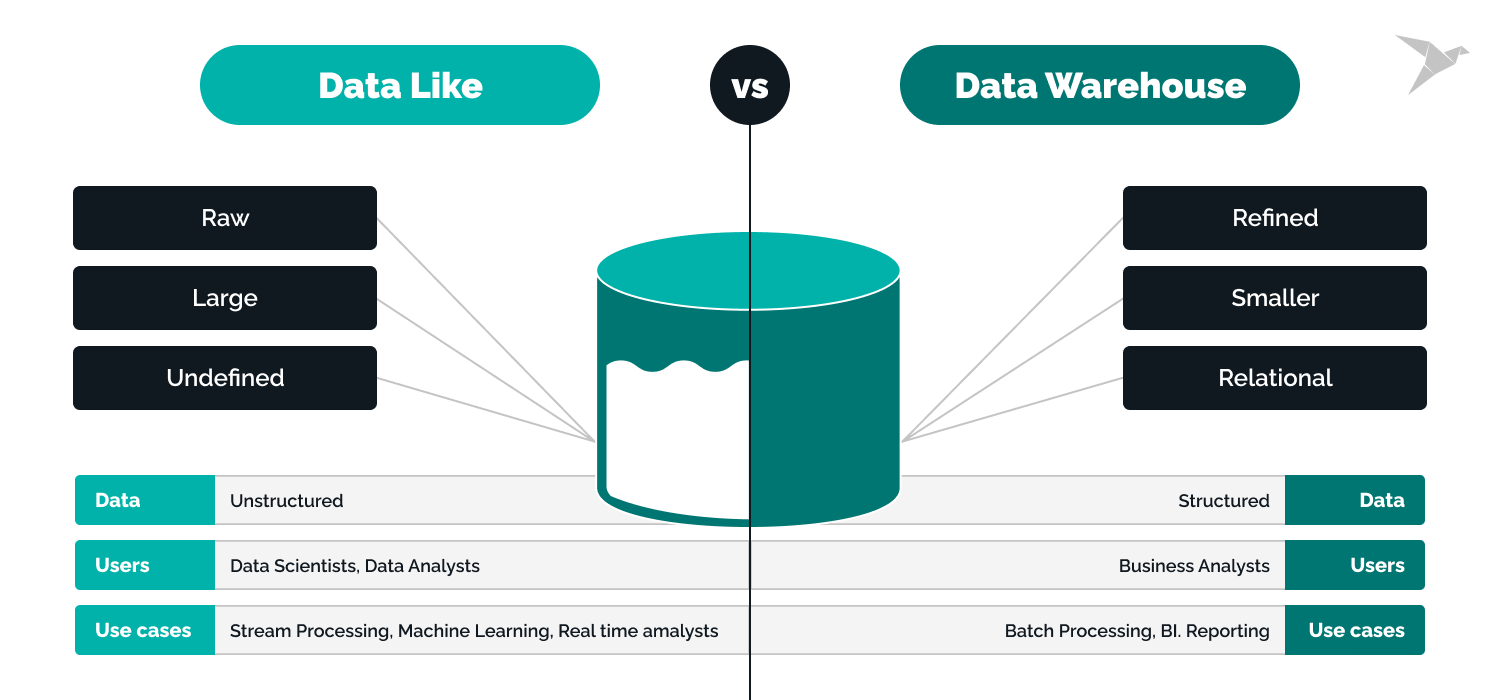
Storage and organization
Data lakes excel in their ability to ingest a wide range of data types, holding raw data until it's ready for processing. This flexibility, while advantageous, demands meticulous data governance to avoid becoming a data swamp.
On the other hand, data warehouses prioritize structured data, emphasizing performance and the ability to answer precise queries swiftly. They offer a well-organized environment that simplifies analytics. However, this structured approach can limit their adaptability to changing data types and sources.
Data lakes are the go-to choice for those seeking comprehensive analysis of extensive data (from social media, IoT devices, and logs) collected over prolonged periods. In contrast, data warehouses facilitate operational processes and day-to-day activities (sales transactions and customer information).
Note: Data warehouses often lean towards a more structured approach, promoting better data management practices and reducing complexity during data consumption. Thanks to their pre-packaged features and robust SQL support, data warehouses offer swift, actionable querying.
Data variety and types
Data lakes preserve data in its original form, including intricate ones like IoT device logs, images, videos, and more. Transactional data from CRM and ERP systems also find their home here. Structured Query Language (SQL)-friendly territory, data warehouses accommodate text, numerical, and similar data types, mirroring relational databases.
Scalability and performance
Data lakes provide quicker access to insights as a result of various factors. Data lakes allow access to different data types even before transformation and refinement. However, there's a trade-off. Some data sources might not be as prepared as in a data warehouse, which can challenge certain users. Despite this challenge, data lakes encourage the exploration and utilization of data in creative ways.
Want to launch a robust, easy-to-use, scalable, high-load application?
Learn moreData governance
Data lakes adopt a more adaptive perspective with governance. They're frequently utilized for experimental and exploratory analysis, where data's depth can lead to lower data quality.
Without a predefined schema, data lakes can easily descend into dissonance without robust governance practices. The structured strains of data warehouses resonate with inherent governance. This schema enforces data integrity, ensuring the accuracy of insights.
Data processing mechanisms
Data warehouses can meticulously structure queries and predetermined analytics. However, data lakes show different processing - where exploratory analysis and advanced analytics reign supreme. Here, Hadoop and Spark offer tools for comprehensive exploration and deeper insights.
- Data Warehouses: Extract, Transform, Load (ETL) route. This involves sourcing raw data, cleansing, modelling, and then populating operational data repositories.
- Data Lakes: Adopt the Extract, Load, Transform (ELT) method. Here, data is initially extracted, and transformation follows after analysis, guided by data experts.
Data preservation
Creating a data warehouse involves analyzing data sources, understanding business processes, and profiling data. This meticulous process results in a carefully structured data model optimized for reporting. Deciding which data to include is vital to maintain efficiency.
In contrast, data lakes preserve all data, not just current data but also potentially useful datasets. This extensive preservation allows for analysis across time. Thanks to budget-friendly storage solutions and standard hardware, data lakes scale cost-effectively to handle large volumes.
Main Considerations while Designing Analytics Infrastructure
When it comes to the question of choosing between a data lake and a data warehouse, there's no straightforward answer. Unsurprisingly, data teams often find themselves transitioning from one data warehouse solution to another. As the needs of data organizations evolve to cater to the demands of data consumers – flexibility is key.
Analytics
Reflect on your analytics lifecycle. Data warehouses store historical data, enabling deep retrospective analysis. In contrast, data lakes can ingest real-time streams for up-to-the-minute insights.
With data lakes, data scientists can explore and experiment, uncovering hidden patterns. When data warehouses cater to structured business reporting, delivering predefined insights to decision-makers.
Data processing paradigm
Inspect your data processing paradigm. Data warehouses are adept at batch processing for structured analytics. Data lakes embrace batch and real-time processing, opening doors to data-driven decisions.
Data retention policies
Define your data retention strategy. Data lakes are cost-effective for long-term data retention, catering to compliance and archival needs. Data warehouses, optimized for query performance, might prioritize short-term analysis.
Integration with the ecosystem
Map the data flow across your ecosystem. Data lakes, with their capacity to ingest diverse data types. Data warehouses offer structured integration for specific insights.
Use case
For regular reports drawn from routine queries on frequently updated tables, a data warehouse suffices. However, when your journey includes experimental fields like machine learning, IoT, or predictive analytics, preserving raw, unprocessed data becomes crucial.
It's worth noting that often, the ideal strategy involves both a data lake and a data warehouse. Data warehouses cater to day-to-day operations, offering quick insights, while data lakes accommodate vast data volumes in their raw form, beneficial for advanced analytics and machine learning. A data warehouse is often built atop a data lake, drawing upon its cleansed and structured data.
Structure
If you're already using SQL databases, CRM, ERP, or HRM systems, a data warehouse integrates seamlessly. A data warehouse is an excellent fit if your data is well-structured or can be organized. For varied data sources (think IoT logs, binary data, analytics), data lakes, with their Extract, Transform, Load (ETL) process, might be the wiser choice to avoid significant data loss.
Hybrid Solutions
Consider a hybrid approach. Using data lakes for raw data storage and initial exploration while employing data warehouses for structured analysis offers a comprehensive solution for your needs.
Keep reading to discover more about Data Lakehouse.
Hybrid Approaches: Data Lake and Data Warehouse Integration
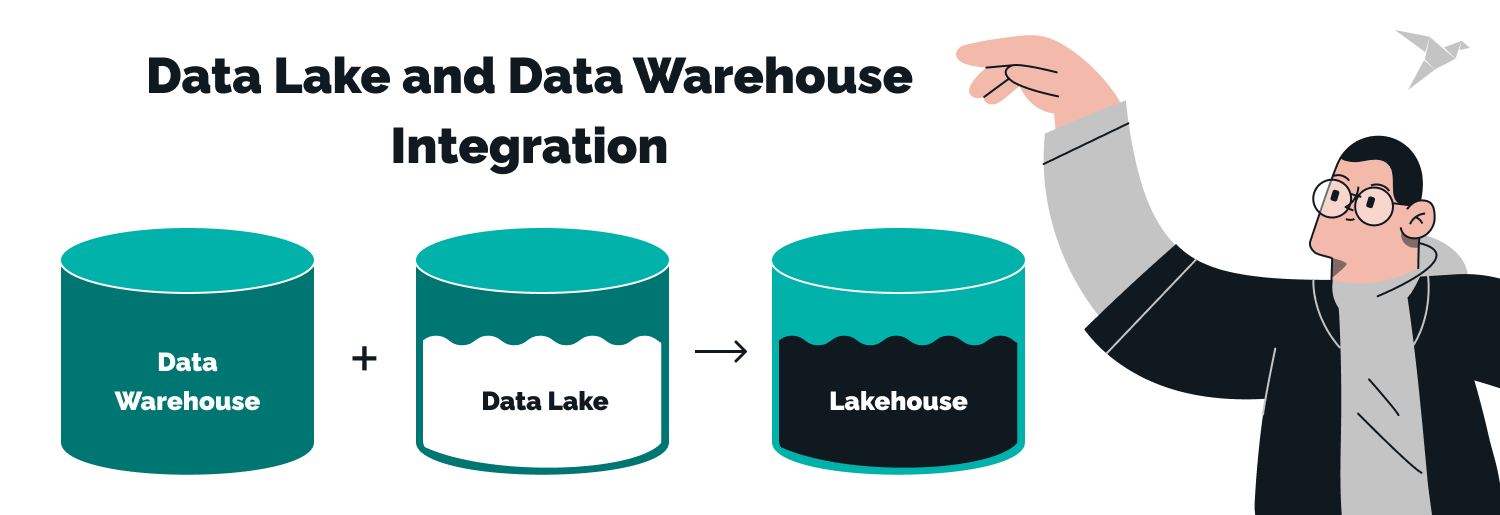
Organizations tap into the scalability, cost-efficiency, and adaptability of data lakes with the hybrid approach. Simultaneously, they draw upon the governance, security, and dependability characteristics of data warehouses. This dynamic combination empowers organizations to unlock deeper insights from their data and make decisions with heightened precision.
Importantly, this approach to modernizing data warehousing doesn't entail scrapping existing technological assets. Quite the contrary, it entails augmenting a data warehouse with a data lake while maintaining the same operational processes. This expansion allows for incorporating additional data sources and analytical capacities by deploying a data lake.
A Practical Example of the Lakehouse Architecture
A data lake is a repository for raw, unstructured, and unprocessed data. It's equipped to ingest a diverse array of data, including SQL and NoSQL data from various sources like CRM systems, marketing analytics tools, and social media platforms.
Later, this data is used to navigate the data lake and identify relevant datasets and sources. These are leveraged to develop tailored algorithms for anomaly prediction, predictive maintenance, and fraud detection.
Using an extract-transform-load (ETL) strategy, specific data types are processed and funnelled to a connected cloud-based data warehouse. After being formatted suitably, this data becomes accessible through self-service BI tools, data visualization software, and analytics solutions, both new and legacy.
Conclusion
Both data warehouses and data lakes are practical tools for modern enterprises. According to TDWI’s Best Practices Report on Building the Unified Data Warehouse and Data Lake (2021), 53% of companies have on-premise data warehouses, and 36% have one on the cloud. However, data lake adoption is still lagging due to its free-flowing nature, larger scale, and architectural complexities.
Data lakes and data warehouses provide a unique set of pros and cons; your decision to implement either will depend on your enterprise’s current and future data intelligence roadmap.
Interested to learn more about TechMagic?
Contact usFAQ

-
1. What is the main difference between a data lake and a data warehouse?
Data lakes store diverse and unprocessed data, including structured, semi-structured, and unstructured formats. Data warehouses, on the other hand, organize structured data meticulously into tables, columns, and rows, facilitating swift query processing.
-
When should I consider using a data lake for analytics infrastructure?
Data lakes shine when dealing with unstructured data, enabling advanced analytics and accommodating massive datasets. They are perfect for exploration and experimentation, useful in scenarios like machine learning or discovering new insights.
-
What are the advantages of a data warehouse for analytics purposes?
Data warehouses excel in structured data analysis and reporting. They offer data governance, security, and reliability, ensuring accurate and consistent results. This makes them fit for operational tasks and generating predefined insights.
-
Can I combine a data lake and a data warehouse in my analytics infrastructure?
Absolutely. Combining the two allows you to leverage the strengths of both worlds. Utilize the flexibility and scalability of data lakes for diverse data storage while a reliable environment of a data warehouse for analysis.
-
How do data governance and data integration play a role in designing the analytics infrastructure?
Data governance ensures data accuracy and security, which is particularly vital for data warehouses. Data integration orchestrates seamless data movement between the lake and warehouse, ensuring a unified and comprehensive analytics experience.
-
What factors should I consider when choosing between a data lake and a data warehouse?
Consider your data types, analysis requirements, processing techniques, and scalability needs. Choose a data lake for exploration and unstructured data, while a data warehouse is optimal for structured analysis and operational insights.


 linkedin
linkedin
 facebook
facebook
 twitter
twitter

















