 Software Development
Software Development
 Security Services
Security Services
 Cloud Services
Cloud Services
 Other Services
Other Services










 TechMagic Academy
TechMagic Academy
AWS Data Pipeline: 4 Reasons To Use It In Your App

Director of Cloud and Cybersecurity, AWS Expert, big fan of SRE. Helps teams to improve system reliability, optimise testing efforts, speed up release cycles & build confidence in product quality.

Over the past decade, data has become the core value creator for businesses. In this post, we explain how to use Data Pipeline to easily move, analyze, and transform data for your application.
Survey data from Experian indicates that 85 percent of businesses see data as one of their most valuable assets. Yet at the same time, researchers at DataProt tell us that businesses say 88% of customer data is irrelevant.
This apparent dichotomy leads us to two possible conclusions, which almost certainly have some degree of merit. The most obvious, if we take both statements at face value, is that creating value from data is a little like sifting piles of sand for a few grains of gold. The second possible conclusion is that DataProt’s respondents are mistaken and do not understand the power of what they possess.
Unraveling that is important but is secondary to the main issue that concerns us today. Businesses continue to gather more and more data with every passing year. They must have some coherent way of handling data catalog of, archiving data sorting, processing and storing it. If not, data becomes an end in itself, and widget companies devote more attention to streaming data about creating and selling widgets than to creating and selling widgets.
Let's get started with the AWS data pipeline definition!
AWS Data Pipeline
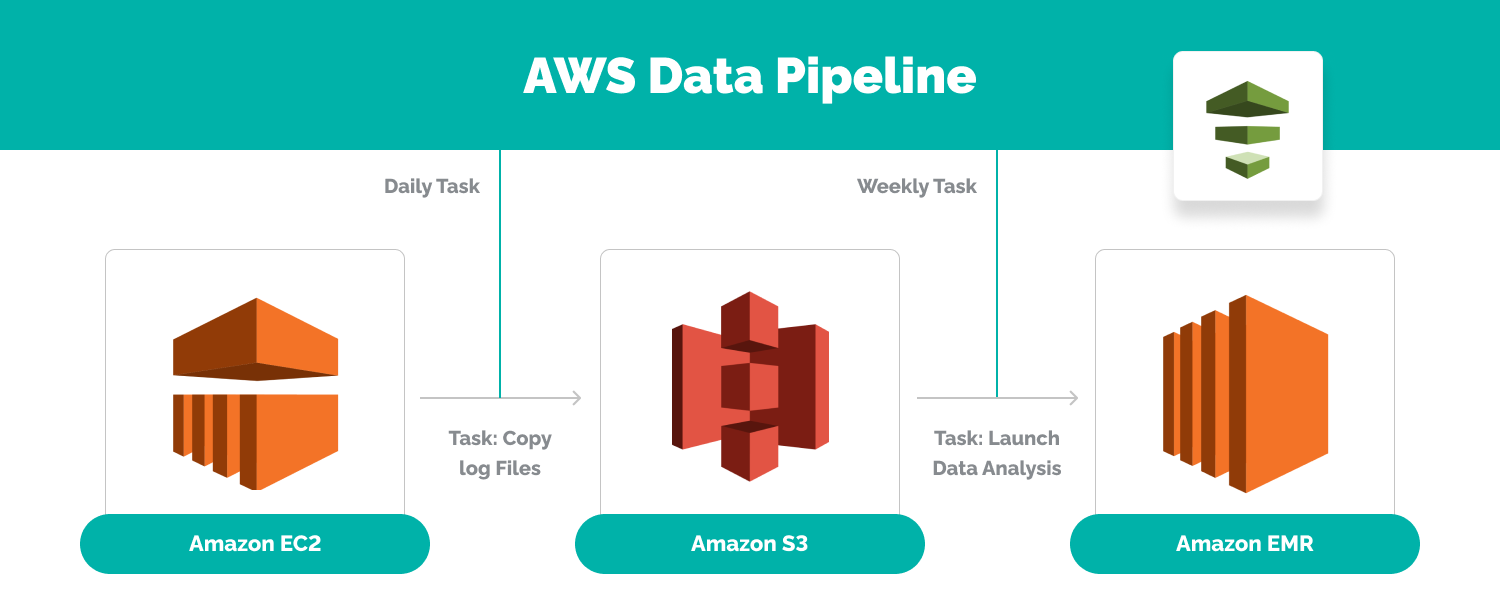
All this is just one reason why data pipeline management is so important. Amazon Web Services Inc’s Data Pipeline is a web service designed to facilitate the processing, efficient transfer and transference of data between different locations.
The word pipeline conveys the idea of channeling the data between points, but the processing aspect is just as important, arguably even more so. While in the pipeline, the data is transformed, optimized, aggregated or otherwise processed so that it is usable at its destination.
AWS data pipeline helps businesses to create their own ELT infrastructure, as developers can instead use a range of pre-defined templates. Most operations performed by AWS Data Pipeline are powered by Amazon’s services, such as Amazon EMR.
Why Do You Need a Data Pipeline?
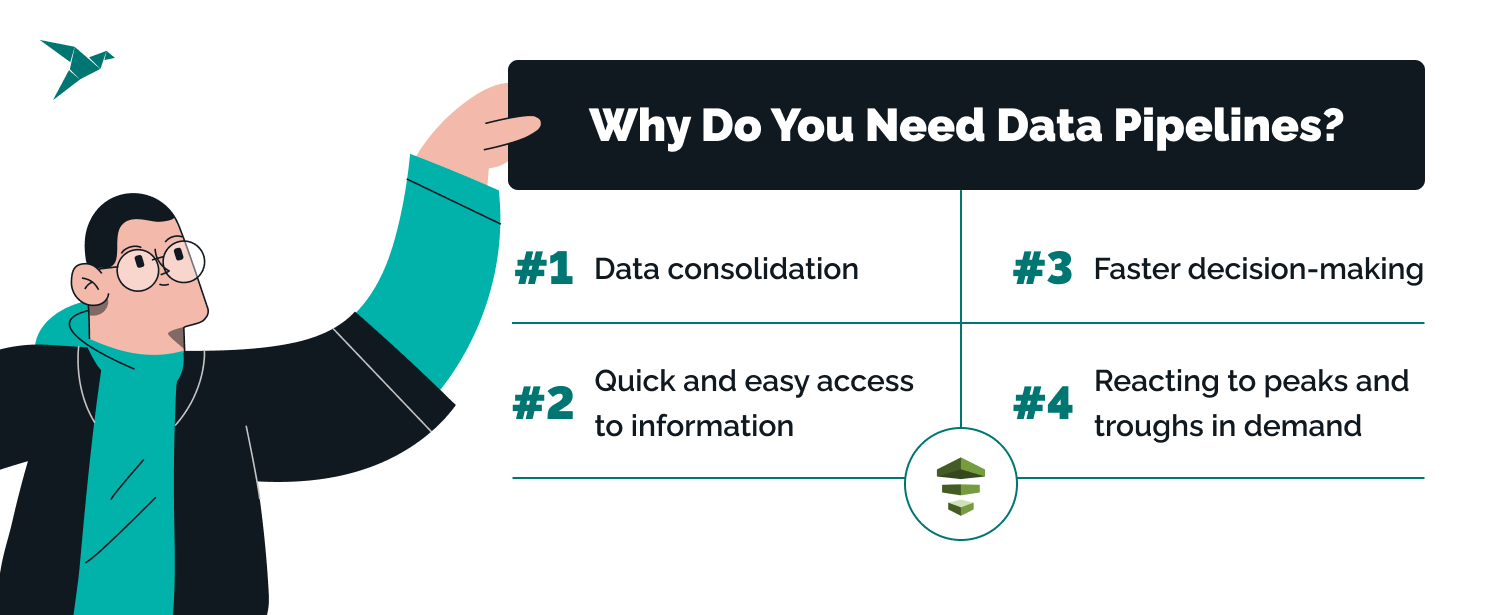
There are plenty of tech solutions that promise to transform businesses, and nobody can afford to invest in all of them. Any good CEO will ask why data pipeline technology should get the nod over other competing projects or software innovations.
Every business will have its own industry-specific answers to that question, but here are four broad-brush applications of AWS Data Pipeline or one of the competing pipeline solutions we defined from our experience delivering data engineering services.
1. Data consolidation
The broad adoption of cloud technology has been a two-edged sword. Today’s businesses use a whole suite of software and apps for different purposes. From one team to another, you might find disparate tools in use that store similar or related information such as warm leads, customer feedback and so forth.
Fragmented and siloed data is of no use to anyone and using it to derive any meaningful strategic insights becomes more trouble than it is worth. A data pipeline consolidates data into a common destination, eliminating duplication data silos, and redundancy.
2. Quick and easy access to information
If you walk into a cake shop, you don’t want to be presented with flour, sugar, butter and milk. That’s essentially what raw data gives you. Amazon data pipeline extracts the raw data and performs the necessary processes on it so that it can be usefully interrogated by analytics software - hey presto, useful insights on topics like buyer behaviour that are even better than a delicious cake.
3. Faster decision-making
Today’s business world moves at a faster pace than ever before. It is vital that everyone in the company, and especially anyone in a customer-facing role, has the information on-hand to make the right call without delay.
That data analysis could be almost anything, from some trending craze that is causing a shift in buyer behavior to a supplier issue that could affect the entire supply chain to basic customer data that facilitates a responsive service. Data pipelines help companies have instant access to the data they need to make the right calls and leverage every opportunity to transform data.
4. Reacting to peaks and troughs in demand
Whether it is through natural growth or seasonal changes in demand, traditional information pipelines tend to struggle with increases in demand and have very limited scalability. That shouldn’t be a problem with a data pipeline like AWS, which is instantly scalable to any size.
Looking for AWS experts?
Learn moreWhat Are the Components of AWS Data Pipeline?
AWS Data Pipeline consists of several key components that work together to enable the efficient movement and transformation of data for intelligent business insights. Let's explore each of these components in detail:
- Data pipelines are the core building blocks of AWS Data Pipeline. They define the flow and processing of data from various sources to destination locations such as organizations' data centers. A pipeline consists of a series of activities and resources that manipulate a million files of data as it moves through the pipeline.
- Data nodes represent the data source or destinations within the AWS data pipelines. They define data movement and where it should be stored. It supports various types of data nodes, including:
- SqlDataNode
- DynamoDBDataNode
- RedshiftDataNode
- S3DataNode
- Task runner is responsible for executing the activities defined in the pipeline. It runs on a compute resource and performs the necessary actions, such as data extraction, transformation, and loading. The task runner ensures the smooth execution and error handling of the pipeline activities according to the defined schedule and dependencies.
- Activities are the individual tasks performed within pipeline. Each activity carries out a specific operation on the data, such as data transformation, aggregation, or filtering. AWS Data Pipeline provides various built-in activities, such as ShellCommandActivity, HiveActivity, EMRActivity, and more. Additionally, you can create custom activities using its activity templates.
- Pipeline Log files generate log files that provide detailed information about the execution and status of the pipeline in a moment. These log files capture important metrics, error messages, and diagnostic data, which can be valuable for troubleshooting and monitoring the pipeline's performance.
How does the AWS Data Pipeline work?
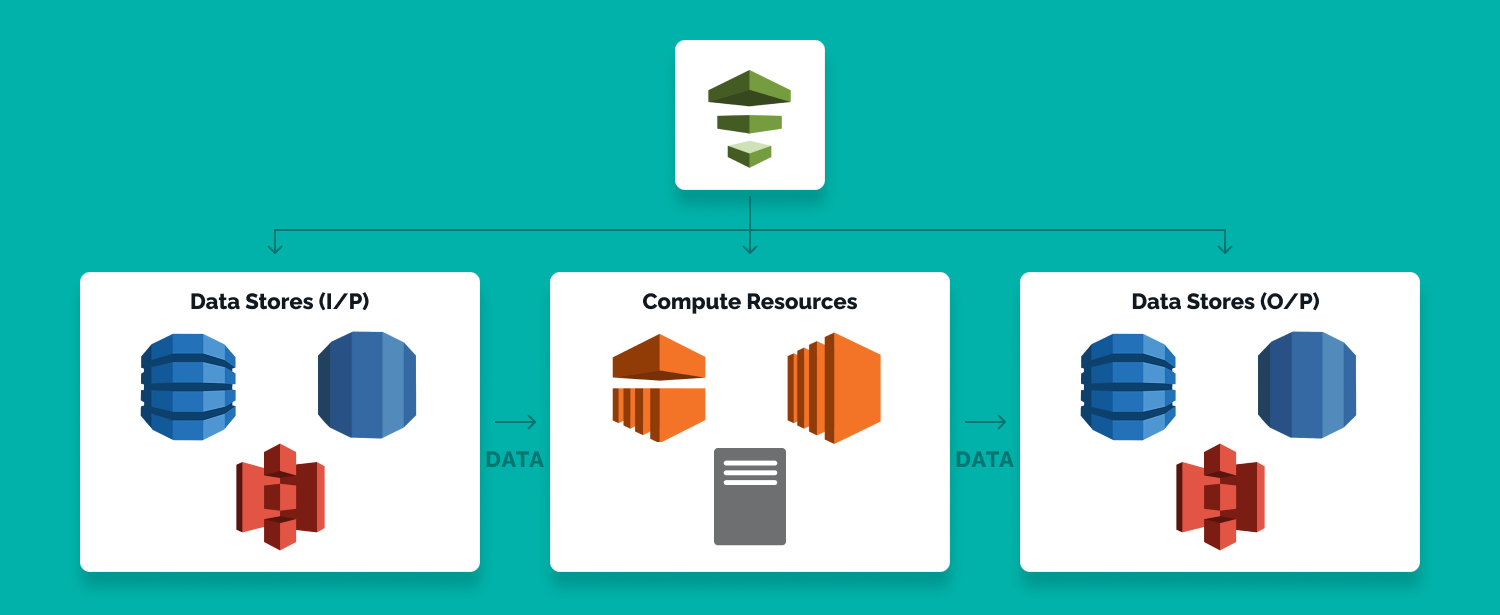
Data sources are fed into the pipeline at specified intervals. This data source is likely to be unstructured and might come from almost anywhere across AWS compute. Examples of data sources include a business’s CRM system, IoT sensors, social media tools, and so on.
Next, it is transformed and moved to a destination location, for example, a data warehouse, periodic SQL queries or a data lake such as Amazon S3. This processing is sometimes described as data flow and is essentially an ELT process data.
End users can also log files and other data node and then interrogate the data without needing to work on it any further, using a tool like Amazon Athena.
Why does AWS stand out?
AWS is not the only data pipeline service in the world. Indeed, we will look at some alternatives. However, it does have certain properties that make AWS services stand out from the crowd.
Simple user interface
Very little training is needed. The tool has a user interface that is intuitive and provides easy access to a number of computational resources and predefined. templates for data transformations. Users can set quite complex workflows in motion with just a few clicks.
Multiple sources and destinations
It can process data flow between disparate sources and destinations. These include not only AWS data sources ranging but also most of the popular on-premise data sources such as JDBC-based databases and so on.
Contingency scheduling
Users can schedule operations on a chain basis contingent on the success or failure of upstream tasks.
A range of transformation options
AWS Data Pipeline can support data transformations through different frameworks and operations such as Hive Activity, SQL Activity, etc. It can also perform custom transformations on user defined code, using HadoopActivity.
Compatible with on-premises systems
Users can run AWS Data Pipeline with their internal data systems for data transformation, using data pipeline task runners.
Flexible pricing
AWS provides a flexible pricing structure such that the user is only required to pay for time that resources are actually in use, with a flat fee chargeable for periodic tasks.
Comprehensive security protection
A full security suite provides comprehensive protection of data at every stage of data flow, whether it is in motion or at rest on premises data sources. Granular access control provides close control over exactly who has access to transfer data and to what.
Get valuable insights from your data!
Learn moreAdvantages of Working with AWS Data Pipeline

So much for stated benefits, before you dive in and book an appointment with TechMagic’s AWS Migration Consulting team, let’s look at some of the specific advantages of AWS Data Pipeline according to users. We will then look at any negative aspects or experiences before setting AWS Data Pipeline alongside some alternative solutions you might want to shortlist.
Low Cost
By any standards, AWS Data Pipeline is inexpensive. Usage is billed at a highly competitive monthly rate and users are only required to pay for what they use. What’s more, AWS account is highly forthcoming regarding free trials and credits.
Flexibility
It is capable of either running SQL queries directly on the databases or it can configure and run such tasks as Amazon EMR. Beyond that, AWS Data Pipeline can also facilitate data analysis and processing by executing custom applications at user data centres and data warehouse for loading raw data in a minute.
User-Friendly
AWS Pipeline is easy to use and with a little help from reliable AWS Consulting Services, users will be using the drag and drop console functionality to design their data pipelines in no time at all. There’s no lengthy writing of code, just simple templates that snap together in a way that is intuitive and enjoyable to use.
Scalable
The beauty of it is that once it is in place, it naturally grows with the businesses of all sizes, and even if a company shoots up in size over its first five years, increasing turnover and headcount by a scale of 20 or 50, AWS will take it in its stride. The truth is that as far as loading data onto it is concerned, is can process one file or one million, either in parallel or one after another.
A Reliable Name
The AWS Data Pipeline is built on trusted architecture - more trusted than you might guess. A US nationwide survey by Morning Consult found that people have more trust in Amazon than in the government or police. That trust extends into the business community. Users feel confident using AWS Data Pipeline with services like Amazon EC2.
Highly Transparent
Users respond positively to having absolute control over the compute resources that they need to execute tasks. As there is a comprehensive log of all activities saved in Amazon S3 storage services, users can quickly see network logs and check the status of tasks in the pipeline.
Are There Any Downsides to AWS Data Pipeline
Clearly, AWS Data Pipeline has a lot going for it. But there are pros and cons to everything, and there are a couple of areas in which Amazon’s product does not score so well.
Lack of third-party integration
The AWS data pipeline works like a dream in the AWS service ecosystem and integrates smoothly with other AWS components. However, integration capability with other third party services is negligible.
It can get complicated
Juggling data pipelines and on-premise compute resources can easily overwhelm the unwary. You can soon find yourself trying to handle multiple installations and configurations at once. It’s not so much of an issue for anyone experienced in using other AWS applications, but if you are coming in cold, there’s a steep learning curve.
What Are the Alternatives to AWS Data Pipeline?

From the above, we can conclude that there are more pros than cons when it comes to AWS Data Pipeline. Let’s finish by having a look at some of the other options that are out there and seeing how they measure up in comparison.
AWS Glue
While it would be wrong to suggest Amazon has completely cornered the market, it’s certainly the case that for many, it is not so much a case of whether to use Amazon as it is of which of their products to use, AWS Data Pipeline or AWS Glue.
The latter is a fully-managed ETL service, and while it bears similarities to AWS Data Pipeline, it is more focused on manipulating data catalog and diverse types of data, whereas data pipelines has more emphasis on organizatng and streaming data.
AWS Glue is also serverless and is built on an Apache Spark infrastructure. We won’t dig deeply into that here, but our AWS Serverless Consulting team is on hand to do so if you wish.
Hevo
As mentioned above, the AWS data pipeline is not without its cons. In particular, easy jobs can soon become complex if they or any part of them stands outside the AWS universe. Under such circumstances a platform like Hevo might make more sense.
This fully managed data integration platform does not have the depth and complexity of AWS Data Pipeline but that could conceivably be a good point. It really depends on the relative complexity of what you are doing with it.
Hevo does the heavy lifting on data preparation so that you can focus on core business tasks and get the optimum business value from the insights it delivers with minimal distractions and data loss.
Apache Airflow
We referenced a few well-known business idioms earlier. Well, the open source Apache Airflow workflow engine is a perfect example of the KISS principle in action. It’s laid out with all the business logic, and simplicity of a Toyota and any amateur can master it in no time. It is more of a workflow manager than a big data tool as such data lake.
FiveTran
This no-nonsense cloud-native data extraction tool is attracting some great reviews from SMEs. It simplifies and streamlines data flow using a zero-maintenance pipeline. It lacks the elegance of the other options - no slick user interface or console here. However, analysts have been impressed by its speedy data analytics with regularly access, which promotes fast and efficient insight-driven decision-making. With a free 14-day trial for interested users, it is well worth a look.
FAQs

-
What is AWS Data Pipeline?
AWS Data Pipeline is a web service that facilitates the processing, transformation, unification and movement of large amounts of data from diverse sources to destinations such as data warehouses and data lakes
-
Who should use AWS Data Pipeline?
Data engineers use AWS Data Pipeline to facilitate data processing and flow. However, the data that it provides at its destination can be used by decision makers throughout a business to make strategic insights.
-
What are the alternatives?
There are other data pipelines available, but all have different strengths and weaknesses and will have different levels of appeal to diverse user types. Examples include AWS Glue, Apache Airflow, Hevo and FiveTran
-
What is the difference between AWS Data Pipeline and AWS Glue?
AWS Glue runs ETL tasks in a serverless environment powered by Apache Spark. AWS Data Pipeline can also use alternative engines such as Hive or Pig. For ETL tasks that do not demand the use of Apache Spark, AWS Data Pipeline is likely to be the preferable choice.
-
How much does AWS Data Pipeline cost?
AWS Data Pipeline is priced according to activities and preconditions configured in the user console and their frequency of use. In other words, you pay for what you use. AWS classifies frequency of executions as “low” when an activity is executed up to once per day, or as “high” if it is executed more than once per day.


 linkedin
linkedin
 facebook
facebook
 twitter
twitter

















