














 TechMagic Academy
TechMagic AcademyFHIR App Made Fast: How To Leverage Medplum Capabilities
Last updated:26 February 2026



Speed is one of the most misunderstood goals in healthcare software. Teams adopt FHIR, pick a modern platform, expect momentum, and… stall when compliance, access control, and operations surface late.
Most delivery delays come from missing features AND early architectural decisions that didn’t account for real clinical, regulatory, and operational constraints.
So, in our new article, we explain based on our real practice what it actually takes to build a FHIR-based healthcare app fast and ship it into a real environment without rework. You’ll see what “production-ready” really means in healthcare, why FHIR standardizes data but not delivery, and how Medplum works as a FHIR backend and operational layer rather than a full EHR.
We also break down a 12-week delivery model based on real projects, showing how early compliance decisions, embedded automation, and event-driven design reduce risk week by week. If you’re trying to move quickly without trading speed for stability, this guide maps the decisions that make fast delivery possible.
Key takeaways
- Fast delivery requires early compliance decisions.
- FHIR reduces data ambiguity, not delivery risk.
- Automation works best when embedded in the platform.
- Event-driven design simplifies healthcare workflows.
- Self-hosting offers control but adds operational responsibility.
- A clear delivery model matters more than tooling alone.
What Does "Production-Ready" Mean for Healthcare Applications?
By and large, "production-ready" means compliant, secure, observable, and operable from day one.
A production-ready healthcare application can run in a real clinical environment without workarounds. Compliance, security, monitoring, and operations are built into the system before launch. Logging, access controls, data validation, and failure handling are part of the core design, not added later.
Healthcare apps must meet regulatory, audit, and data integrity requirements before launch
Before going live, healthcare software must support audits, trace data access, and preserve data accuracy over time. This includes role-based access, immutable audit logs, controlled data changes, and clear ownership of PHI. These requirements shape how systems store data, expose APIs, and manage user actions.
Speed only works when architecture decisions are correct early
Fast delivery depends on early technical decisions that hold up under scale and regulation. Shortcuts in data modeling, access control, or integration design slow teams down later. In healthcare, reworking core architecture after launch often means compliance risk, downtime, or data migration issues.
FHIR provides a shared data model, but not a delivery discipline
FHIR standardizes how healthcare data is structured and exchanged. It does not define how to run the system in production. Teams still need to design deployment workflows, monitoring, access policies, and operational controls around the FHIR model to meet real-world requirements.
Medplum acts as the FHIR backend and operational layer, not a full EHR
Medplum provides a production-grade FHIR server with authentication, audit logs, and operational tooling. It supports compliant data storage and integration workflows but does not replace clinical workflows or user interfaces. Teams still design and build the application logic and user experience on top of it.
How the 12-Week Healthcare App Delivery Model Works in Our Practice
Let’s walk through the main working points based on our experience.
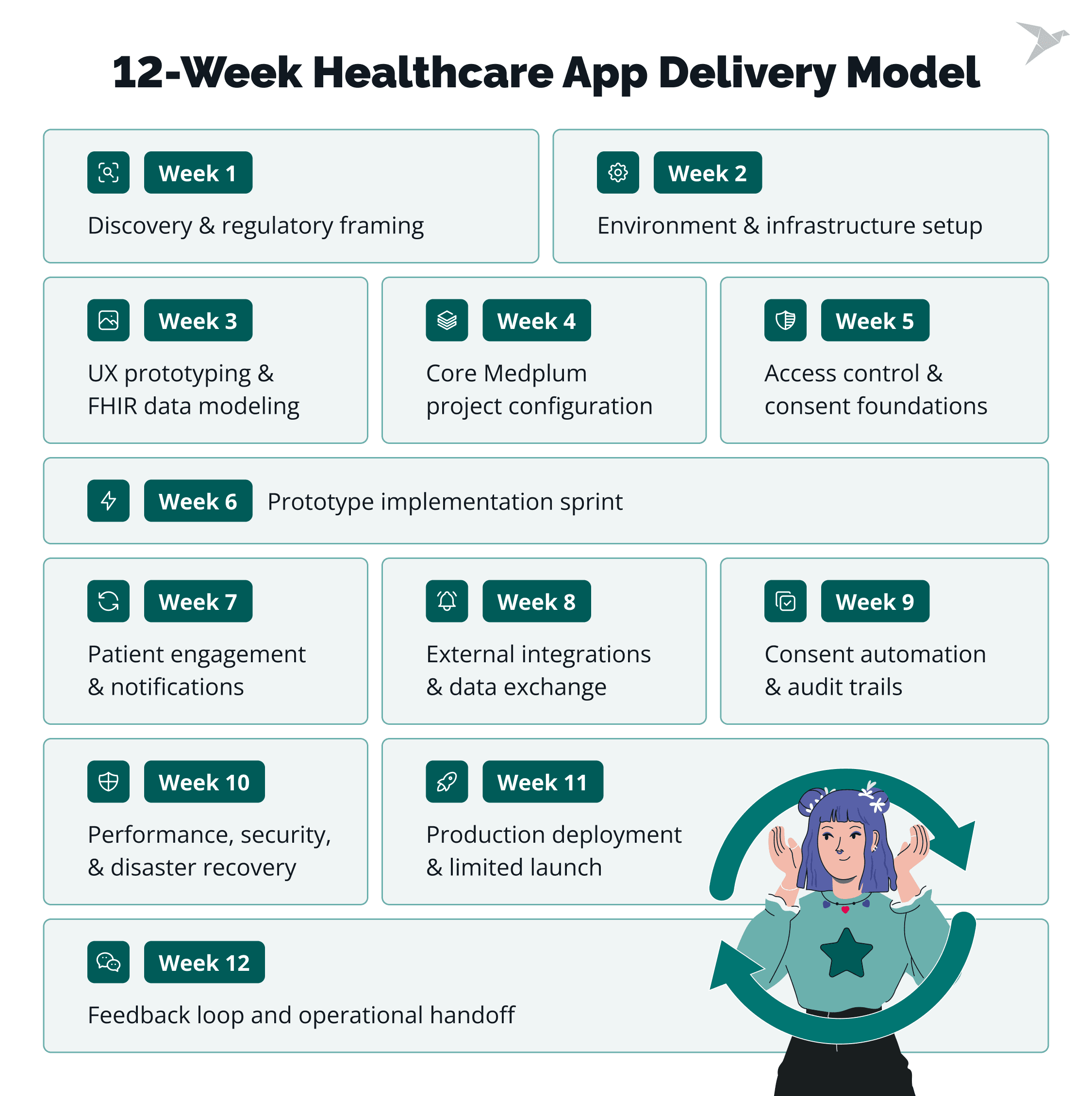
Delivery is structured as sequential, dependency-aware phases
In our projects, the order of work matters as much as the work itself. We run deliveries in clear phases because healthcare systems have real dependencies.
Data models come before APIs. Access rules come before workflows. Infrastructure comes before UI polish. This sequence comes straight from what we’ve seen break when teams try to do everything at once.
Each week reduces downstream risk
We plan each week to remove one or two risks that can derail the release later. Early weeks focus on things that are expensive to fix late: data quality, permissions, auditability, and integration contracts.
Week to week, we aim to make the "unknowns" smaller, so the team spends less time firefighting and more time shipping.
Compliance, data modeling, and automation are handled early
From experience, compliance can’t be a final checklist item. We bring it in from the start: what needs to be logged, what must be traceable, who can see what, and how data changes are recorded.
In parallel, we set up automation for tests, deployments, and validation early. This gives the team fast feedback and keeps releases predictable.
UI, integrations, and workflows are layered progressively
Once the core is stable, we build up in layers. First, the UI supports the most critical user tasks. Then we add integrations, expand workflows, and tighten edge cases. This approach reflects how we’ve delivered safely in healthcare: every new layer sits on top of data and access rules that are already proven.
The goal is a usable, auditable system
We use this model because we’ve learned what "done" needs to mean in healthcare. By the end of 12 weeks, the system should be usable by real people, with real data, and ready for audit expectations. The objective here is a product you can run, monitor, and extend without rebuilding the foundation.
Week 1–3
Weeks 1–3 set the foundation we rely on for the rest of the delivery. From our experience, most healthcare rework comes from three gaps: unclear compliance expectations, shaky environments, and UX that doesn’t match the data model. This phase closes those gaps early.
Here’s what we aim to lock by the end of week 3:
- Clear compliance scope and audit expectations.
- Stable environments, CI, and secret handling.
- UX flows that match the FHIR data model and consent rules.
Week 1: Discovery and regulatory framing
We align product, clinical, security, and engineering on what “ready to launch” means, what constraints are non-negotiable, and how success will be measured. Then we define practical personas (patient, clinician, admin) focused on tasks and access boundaries. This becomes the input for permissions and workflow design.
We map regulated data flows: where PHI appears, how it moves, and who touches it. This helps us spot risky paths early, such as PHI leaking into logs or being shared across roles.
Next, we turn HIPAA, SOC 2, and GDPR needs into concrete system expectations: audit trails, access controls, secure handling, retention, and incident processes. Writing this down early keeps compliance work steady and predictable.
We also inventory existing systems and data sources (EHRs, scheduling, identity, billing, exports) and set service boundaries: what belongs in the FHIR backend, what stays in app services, and what lives in the UI. Getting boundaries right here avoids rewriting logic when integrations or compliance requirements evolve.
Week 2: Environment and infrastructure setup
We treat platform readiness as core product work. We lock toolchain versions so local, CI, and production behave the same. This prevents “works on my machine” issues that drain time later.
We set up shared local environments, provision sandbox cloud (or Medplum Cloud tenants), and establish infrastructure-as-code baselines for networking, compute, storage, and access policies. These baselines make changes trackable and reviewable.
We build CI pipelines and secret management early, then enforce secure builds from the first commit. In our projects, this is the easiest way to avoid late cleanups and last-minute release blockers.
Week 3: UX prototyping and FHIR data modeling
We prototype the core workflows first (patient intake, scheduling, and telehealth) and use them to validate assumptions before implementation. Then we confirm the FHIR resources and relationships behind those flows, so UI and API work is built on a model that supports scale and audits.
We identify consent points inside the user journeys and trace how consent affects access and sharing. This keeps consent enforcement connected to real actions, not treated as a separate feature.
To reduce rework, we map each flow to data events early: what gets created, updated, linked, and logged. This alignment between UX and data is where we usually save the most time later.
digital platform for medical form management

Week 4–6
Weeks 4–6 are where things start to feel real. In our experience, this is the point where healthcare teams either get a clean, controlled setup or end up chasing permission bugs and config fixes for weeks. Our approach is simple: set up the Medplum foundation the right way, make access and consent enforceable, then ship working flows on top of it.
By the end of week 6, we aim to have:
- A Medplum setup that’s ready for automation and growth.
- Access and consent rules you can test and explain.
- Core user flows working with real data.
Week 4: Core Medplum project configuration
We start by creating a dedicated Medplum project with clear boundaries. This keeps environments organized and makes reviews easier later. Then we enable the capabilities most healthcare apps depend on early (bots, email, and cron) so automation isn’t an afterthought.
We also define how practitioners, staff, and organizations connect in the system. When this is vague, permissions and UX tend to get messy fast. To keep data consistent across screens and integrations, we set up terminology and taxonomies early as well. Finally, we sanity-check the configuration against real workflows like intake, scheduling, telehealth, and admin tasks.
Week 5: Access control and consent foundations
This week is about making security practical. We implement role-based access control for the roles teams use every day: admins, clinicians, schedulers, and patients. The goal is to make access rules clear enough that you can test them, audit them, and explain them without hand-waving.
We also put consent on solid ground. We define consent templates, capture patient permissions with clear scope and timestamps, and connect consent to the exact moments it matters in the UX: onboarding, record sharing, caregiver access, summaries, and telehealth. We back this up with tests and logging so access decisions stay traceable.
Week 6: Prototype implementation sprint
Now we turn design into working software. We implement the approved flows in the frontend and connect them to Medplum through the client SDK, so the product is doing real reads and writes.
To keep momentum without losing quality, we add smoke tests, linting, and basic quality gates early. In our experience, this is what keeps delivery smooth as the scope grows through the rest of the build.
We are here to help

Week 7–9
By weeks 7–9, the system is already usable. Now we make it dependable in daily work. From our experience, this is where healthcare products can fail quietly: notifications happen without a clear trail, integrations drift, or consent rules depend on manual habits. We use these weeks to make the system consistent, traceable, and easier to operate.
By the end of week 9, we aim to have:
- Patient communication that’s automated and fully logged.
- Integrations that behave predictably in staging, in both directions.
- Consent enforcement and audit trails that hold up in review.
Week 7: Patient engagement and notifications
We build invitation flows that let patients join securely and with clear intent. The steps reflect how patients actually enter care programs, not an ideal onboarding path.
We add reminders for appointments, forms, and follow-ups, with clear rules for timing, channels, retries, and failures. Bots handle messaging based on real system events, so clinical teams don’t have to coordinate manual follow-ups.
Every interaction is logged: what triggered a message, what was sent, and what happened next. We also treat email, SMS, and in-app messages as part of the regulated system, so access and execution stay traceable across channels.
Week 8: External integrations and data exchange
We connect to the systems that already hold clinical data – EHRs, labs, or health data networks, depending on the product. Integration logic is implemented with Medplum bots and subscriptions where possible, since this is usually simpler to maintain and easier to audit than adding separate integration services.
Secrets are handled through secure storage and rotation, with no hard-coded credentials and no cross-environment sharing. We validate inbound and outbound flows for structure, completeness, and error handling to avoid silent data loss.
The key milestone is proving bidirectional sync in staging. This is where real edge cases surface, and fixing them here is far cheaper than after launch.
Week 9: Consent automation and audit trails
We finalize digital signature flows so consent is captured in a clear, consistent way—tied to identity, time, and context. Consent artifacts are attached to the relevant FHIR resources, which makes both enforcement and review straightforward.
Consent checks are automated at access time. Reads and writes are evaluated against consent rules without relying on manual discipline.
We also confirm audit coverage across the full execution path:
- UI access;
- API requests;
- bot execution.
By the end of week 9, the system can explain its own behavior. Teams can show who accessed data, under what consent, and through which pathwithout manual reconstruction.
HIPAA-compliant portal for secure medical data records and exchange

Week 10–12
The last three weeks are about running the system with confidence. From our experience, this is where teams either prove production readiness or discover too late that key pieces are missing. We use this phase to remove the remaining operational unknowns and make the handoff straightforward.
By the end of week 12, we aim to have:
- Performance and recovery tested under realistic conditions.
- A controlled production launch with real users.
- Clear runbooks, monitoring, and a prioritized backlog for what’s next.
Week 10: Performance, security, and disaster recovery
We run load and stress tests to see how the system behaves under normal and peak usage. This includes API throughput, background jobs, and notification spikes. The goal is to find limits before users do.
We threat-model the deployment architecture and review where failures or attacks could happen: network boundaries, identity flows, service-to-service access, and third-party dependencies.
We also validate backup and restore, not just backup creation. In our practice, a backup is only real once it has been restored successfully. Key rotation and credential handling are tested in calm conditions, so the process is safe when it matters.
Finally, we lock configuration and secrets in managed stores. This reduces accidental changes and keeps sensitive values out of code and logs.
Week 11: Production deployment and limited launch
We execute the full CI/CD pipeline end-to-end, using the same release path validated in earlier weeks. This confirms that production releases don’t depend on manual steps.
We deploy backend services and infrastructure through infrastructure as code, then ship frontend assets with production configuration, authentication, and monitoring enabled.
To keep launch controlled, we seed only minimal production data and onboard a small pilot group. Then we monitor the system closely under real usage – performance, errors, access patterns, and audit logs. This is where real-world edge cases show up.
Week 12: Feedback loop and operational handoff
We collect structured feedback from pilot users so themes are easy to spot. This helps separate product issues from training gaps or configuration limits.
We prioritize quick wins and critical fixes, then finalize monitoring and alerting so the right signals reach the right people without noise.
We deliver operational runbooks and onboarding documentation, covering routine tasks and incident response. Week 12 closes with clear ownership and a prioritized backlog, so the team can move into continuous delivery without losing momentum.
Common Use Cases We See in Practice
Medplum tends to fit best when a team needs a FHIR-first backend and an operational layer, but still wants to shape workflows and UX on its own terms.
Across our projects, the same product patterns show up again and again. It usually happens in teams that need standards-based data handling without taking on full EHR complexity.
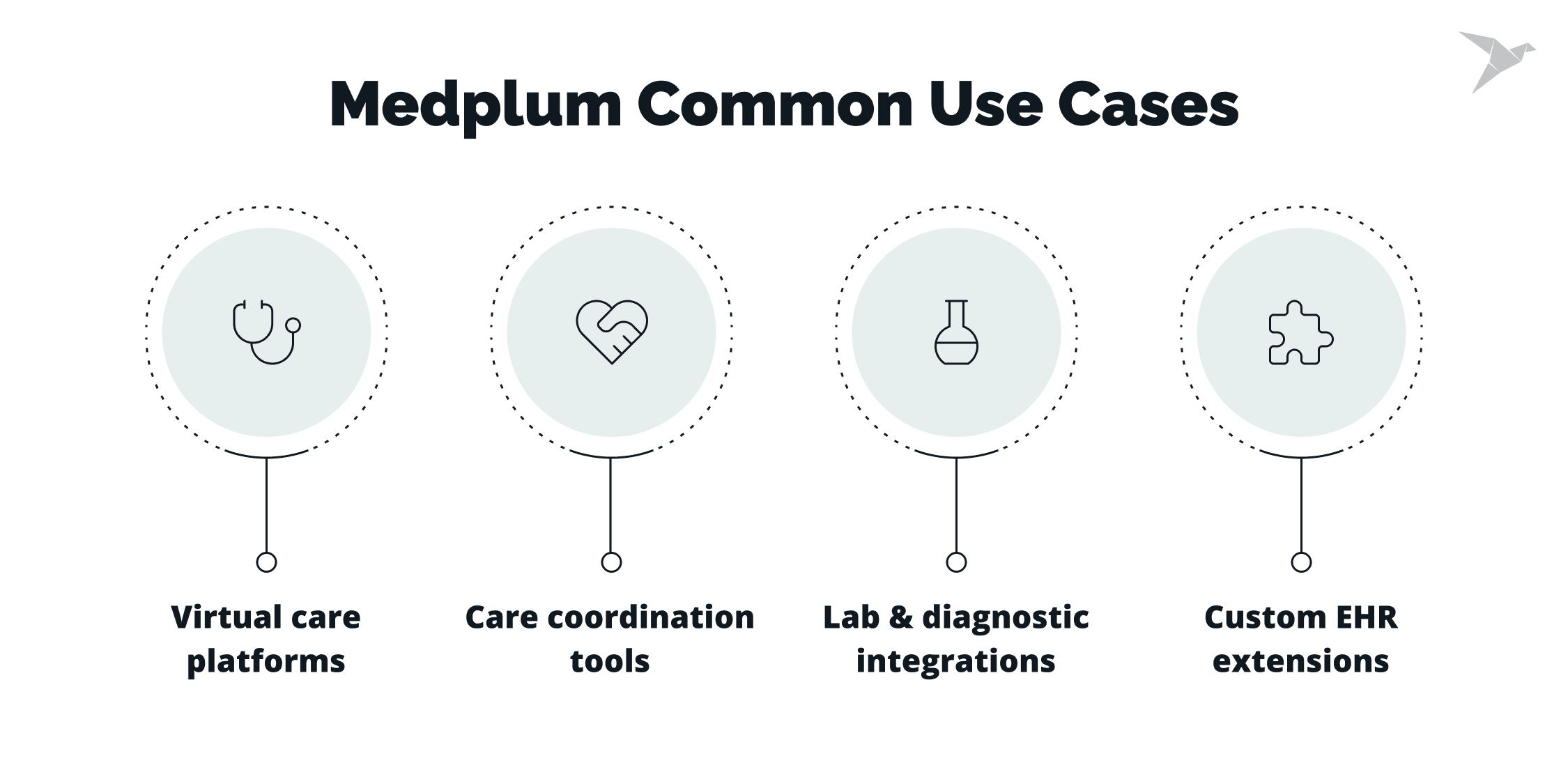
Virtual care platforms
These products usually combine scheduling, visit sessions, and clinical documentation into a single flow. A shared FHIR model keeps encounters, notes, and patient data consistent, while the team remains free to design the visit experience around real clinical practice.
Care coordination tools
Care coordination depends on clear handoffs. The work often comes down to linking patients, practitioners, tasks, and organizations in a way that reflects how teams collaborate across settings. When those relationships are modeled well, coordination becomes easier to operate and less dependent on manual tracking.
Lab and diagnostic integrations
Lab and diagnostic workflows involve orders moving out, results coming back, and updates landing in the right place. Standards-based exchange, combined with bots and subscriptions, helps automate routing, validation, and updates without building custom glue for each connection.
Custom EHR extensions
Many teams aren’t replacing an EHR but extending one. This might mean adding a new workflow, capturing additional data, or supporting a specific clinical program. In these cases, Medplum can serve as the integration and logic layer, allowing teams to move faster without rebuilding core EHR functions.
When Medplum may not be the right choice
From our experience, teams tend to look beyond Medplum when they need a finished solution with minimal build effort and ongoing ownership. If the goal is to adopt a full EHR out of the box, with complete clinical workflows already in place, a dedicated EHR product is usually a better fit.
Medplum can also be a stretch when there are no internal engineering resources. The platform works best when someone owns the application layer, integrations, and day-to-day operation. Without that capability, a platform approach often adds more responsibility than a team expects.
Teams that rely on prebuilt, standardized clinical workflows may also find Medplum less suitable. When customization is limited, and workflows need to stay fixed, more prescriptive solutions tend to align better with those expectations.
For very small or non-clinical wellness products, a full FHIR platform can be more than is needed. In cases with limited regulated data, simpler data models and infrastructure are often enough.
Finally, if the preference is for a turnkey SaaS product that’s fully vendor-managed, Medplum may feel too hands-on. Platform ownership comes with flexibility, but it also requires operational involvement that not every team wants to take on.
Wrapping Up
Fast FHIR app delivery depends on early, disciplined decisions. FHIR removes data ambiguity, but production readiness still comes from clear compliance scope, testable access rules, observable systems, and repeatable deployment.
The 12-week model outlined here reflects that reality: risk is reduced in sequence, from regulatory framing and stable environments to Medplum configuration, RBAC and consent, automation, integrations, and audit coverage. The final weeks confirm readiness through performance testing, recovery checks, and a controlled launch with real users.
If you’re building a healthcare app or EHR extension and want to use Medplum without getting stuck on architecture or compliance tradeoffs, we can help. We design the delivery plan, set up the Medplum foundation, and guide the product through launch and operational handoff.

FAQs

With a clear scope and early compliance decisions, teams can reach a usable, auditable system in about 12 weeks. The key factor is sequencing work correctly, not just writing code faster.
No. Medplum provides compliant building blocks, but teams still need to define access rules, consent logic, audit coverage, and operational processes. Compliance works best when handled early and intentionally.
Medplum is not a full EHR. It acts as a FHIR backend and operational layer. Teams still design and build clinical workflows, user interfaces, and product-specific logic on top of it.
Yes. Medplum supports self-hosting, which helps teams meet data residency, security, and infrastructure control requirements. Self-hosting adds operational responsibility, so it works best with engineering ownership in place.

